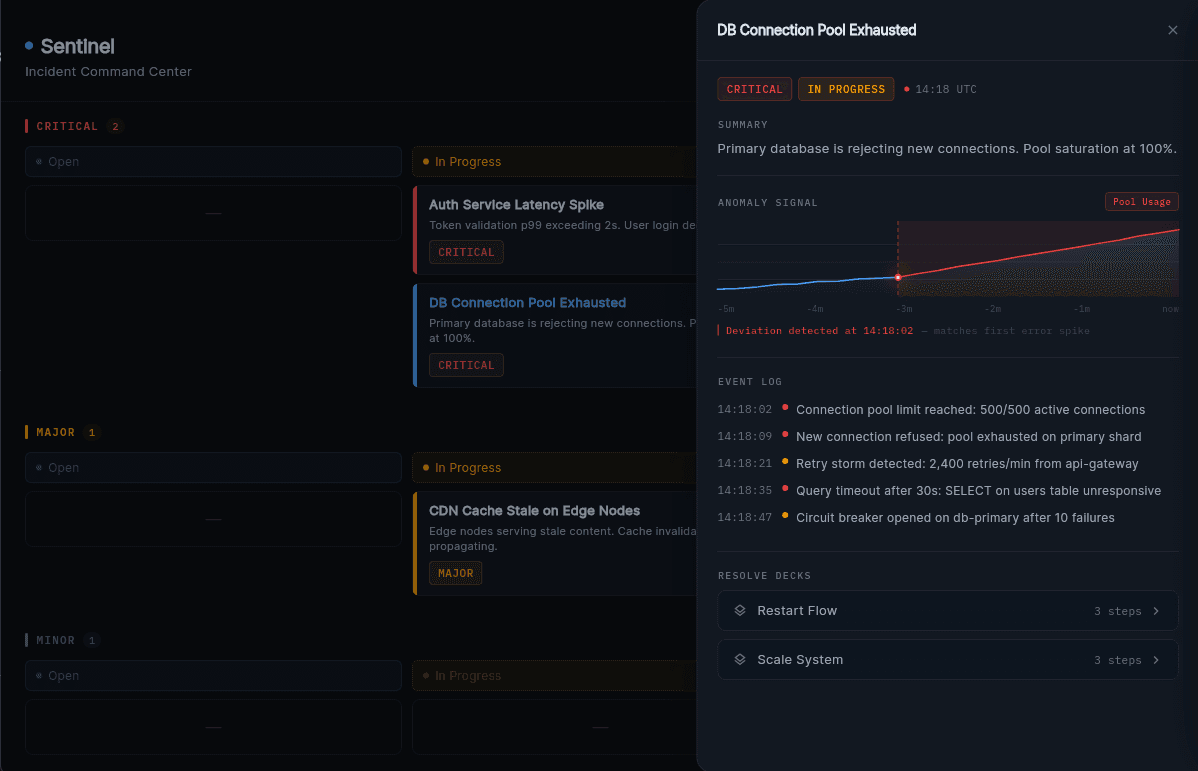
You're not solving incidents. You're repeating them.
Same alerts, different days
Your monitors fire the same alert every week. Your team investigates from scratch — every time. There's no memory between incidents.
Knowledge lost in Slack
The fix lives in a thread from 6 weeks ago. Nobody knows who found it. By the time you search, you've already lost 40 minutes.
I think it was the connection pool again
found it — scale replicas first then check redis
anyone remember how we fixed this last time?
Runbooks that nobody follows
Your wiki has 47 runbooks. In an incident, nobody reads them. They're stale, unstructured, and disconnected from the actual alert.
Three steps to
structured response
Select the Incident
When an alert fires, Sentinel surfaces the incident automatically. No manual triage. No digging through dashboards. The context is already there.
- Alert ingestion from PagerDuty, Grafana, DataDog
- Auto-classification by severity and service
- Historical context from similar incidents
Understand the Context
Sentinel surfaces what matters — past resolutions, affected services, ownership, metrics. You don't search. You respond.
- Linked past incidents and their resolutions
- Service ownership and escalation paths
- Real-time metrics embedded in context
Execute Once, Reuse Forever
Run through the workflow. Every decision is saved. Next time a similar incident fires, Sentinel already knows what to do.
- Live checklist updated by any team member
- Decisions and notes captured inline
- Workflow promoted to template automatically
What Sentinel gives your team
Stop solving the same incident twice.
Choose how you want to experience Sentinel — explore the demo, talk to the team, or get early access.
Get Early Access
Be the first to stop repeating incidents. Join the waitlist — no commitment required.
Let's talk about
your incidents
Whether you want a demo, have questions about how Sentinel fits your stack, or just want to see it in action — we're here.